观点
我的实验智能体遇到了GPU问题,这让我发现了面向智能体的计算
如何为AI智能体设计最原生的基础设施抽象来进行科学实验?
构建用于科学发现的AI智能体
今年,我一直在构建运行科学实验的AI智能体。不是玩具示例,而是真正的研究。想象一下你有这样一个问题:"权重量化究竟如何影响Transformer模型不同层的推理能力?"
要回答这个问题,你需要运行大量实验。你提出假设、设计实验、运行代码、观察结果、改进假设,然后重复。这是实证科学的核心循环。我的智能体就是为了帮助自动化和加速这个循环而设计的。
但除了智能体的智能(自我进化能力)、可重复性和科学严谨性之外,我面临的最大挑战是计算自主性,即AI如何高效地控制和使用计算资源来进行不同的科学实验?

"把智能体放在GPU上"的问题
在我的实验室里,我有一组A40 GPU。看起来很简单,对吧?直接把智能体指向我的本地GPU让它运行就好。但实际上效果很差。原因如下:
问题 #1: GPU空闲问题
AI智能体不是简单地启动一个训练任务就消失了。它需要思考和规划。它需要生成代码。有时候它还要等我审查它的方案。在所有这些时间里?GPU就那样闲置着。
问题 #2: 可扩展性问题
假设智能体想要测试五种不同的实验配置。用一个本地GPU节点,它只能按顺序运行。另一个显而易见的方案是让智能体在基础设施方面更聪明?你可以尝试嵌入一个资源调度器,强制智能体学习如何选择合适的计算资源并提交任务。但这样做太重了。它给智能体增加了一个次要任务的负担,分散了它对科学发现这一主要目标的注意力。智能体最好的接口是生成代码;我们需要一种方式,让它以最小的代码改动就能获得大规模并行能力。
问题 #3: 硬件天花板
我的实验室有A40。它们很棒,但如果我的智能体的研究路径引导它提出了一个需要更强大的H100的假设呢?或者一个CPU密集型任务?我被困住了。智能体被锁定在我手头拥有的特定硬件上。真正的科学探索需要使用合适工具的灵活性,从早期想法的廉价简单实验到后期的大规模严格评估。我的智能体被困在一个金笼子里,强大但不灵活。
面向智能体的计算
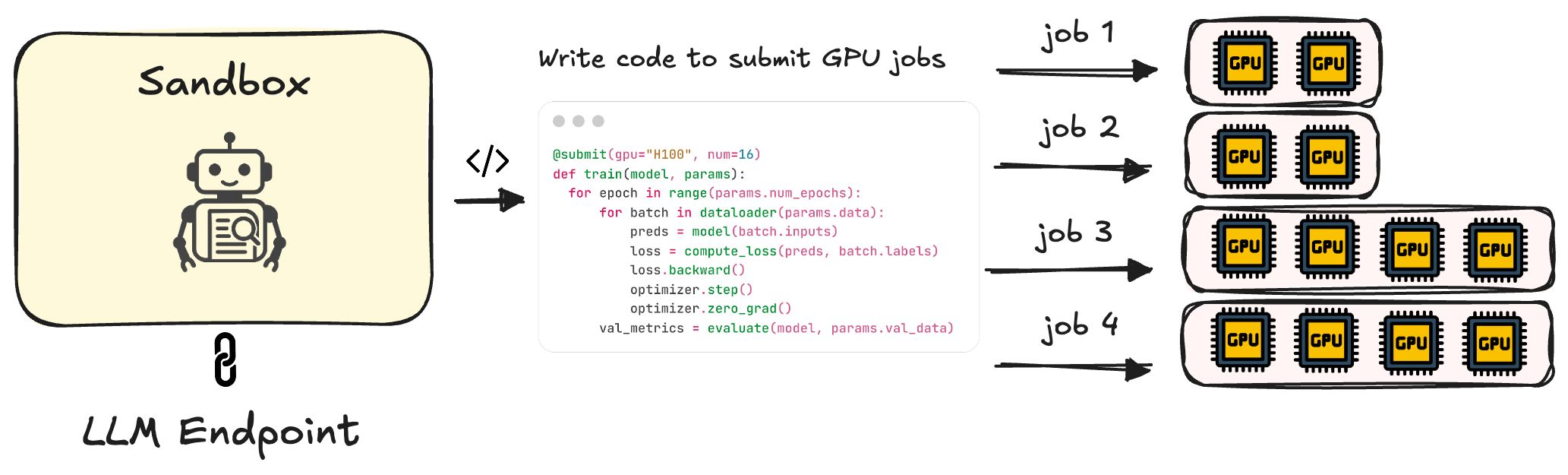
感觉最自然的解决方案,也是我开始称之为面向智能体的计算(Agent-Oriented Compute)的方案。
这个想法很简单: 智能体本身运行在一个轻量级、低成本的沙箱中,在那里进行思考和规划。但当它需要运行严肃的实验时,比如训练模型、运行仿真、处理数据,它不在本地执行。相反,它将任务打包并分派到一个无服务器计算平台,只需最小的代码改动。
这就是我所说的面向智能体的计算: 围绕AI智能体的自然工作流程设计的计算基础设施,而不是基于传统假设来决定任务应该如何运行。
为什么这很重要
我认为我们正处在一个奇妙的转折点。我们正在构建越来越强大的AI智能体,但我们却强迫它们使用为人类提交计算任务而设计的计算基础设施。(另一个反面例子是让AI智能体像人类一样控制浏览器。)
面向智能体的计算不仅仅关乎效率(虽然这一点非常重要)。它关乎释放智能体真正能做的事情。更快的迭代。并行探索。动态资源扩展。这些东西能把"这个智能体很厉害"变成"这个智能体刚刚在一个周末完成了六个月的研究。"
总结
我的方案完美吗?可能不是。我对自己的想法足够挑剔吗?也许不够。但我知道一件事: 当我切换到这种无服务器方案的那一刻,我的智能体从令人沮丧变成了真正有用。
这种无服务器计算范式使我们的智能体能够完成我们一直承诺它们会做的那些宏大目标。
想用AI智能体为你自己的研究运行实验?
试试 Orchestra Research,一个内置面向智能体计算的AI驱动研究平台。