Demo
从零开始,10天内用我构建的AI科学家完成ACL投稿
解码AI研究创新的DNA
我一直在思考如何训练大语言模型变得更有创造力,不只是遵循指令或检索信息,而是像人类研究者那样真正地进行头脑风暴:将现有工作中的线索串联起来,发现下一个机会。
创新不是凭空产生的,那么我们能否解码科学创新?认知科学家研究创造性思维模式已有数十年。但在AI研究领域具体是怎样的?AI研究者如何在前人工作的基础上,将其转化为真正的创新?
如果我们能够捕捉研究者产生创新的方式,那些反复出现的模式,即他们如何在前人工作的基础上将其转化为新想法,我们能否利用这些思维轨迹来训练下一代AI科学家,使其在研究构思方面大幅提升?
我决定在新年假期前启动这个项目,并在1月5日完成了论文投稿。整个研究流程完全开源且透明。
三步解码创新
第一步: 从哪里找到高质量的研究创新案例?
我从顶级会议论文入手,具体来说是 NeurIPS、ICML 和 ICLR 的 Oral 和 Spotlight 报告。这些论文代表了所有投稿中前1-5%的精华,由专家程序委员会评选出最具新颖性和影响力的工作。我让我的智能体 系统性地收集了2023-2025年的论文,共计3,819篇,构成了该领域近年来最优秀工作的大规模语料库。
第二步: 如何提取每项创新背后的推理过程?
每篇论文都在讲述一个故事:之前存在什么,我们发现了什么空白,我们如何在前人工作的基础上创造了新的东西。这种学术综合推理通常是隐含的,编织在引言和相关工作部分中。我让我的智能体 将推理轨迹显式化和结构化。对于每篇论文,我使用大语言模型识别构成其学术基础的关键前驱论文,不是任意引用,而是那些具体的想法、方法或局限性直接塑造了该贡献的论文。然后综合分析作者如何讲述他们的故事:前人工作如何启发当前研究,不同想法如何关联,以及哪些思维跳跃最终导向了创新。在质量控制方面,我在已知前驱论文的论文上验证了流水线,并对低置信度案例使用了多模型交叉验证。

第三步: 数千篇论文中是否存在反复出现的模式?
如果创新是可学习的,那就应该存在模式。并非每篇论文都发明了一种全新的思维方式。研究者们在重复使用认知策略。基于近4,000篇论文的结构化推理轨迹,我让智能体 运行了系统性的模式发现工作流 来识别和量化这些模式,提出的问题是:哪些认知策略在反复出现?
发现: 突破性研究背后的15种思维模式
结果比我预期的更有结构性。在整个数据集中,我识别出了15种不同的思维模式,其中三种占据主导地位:
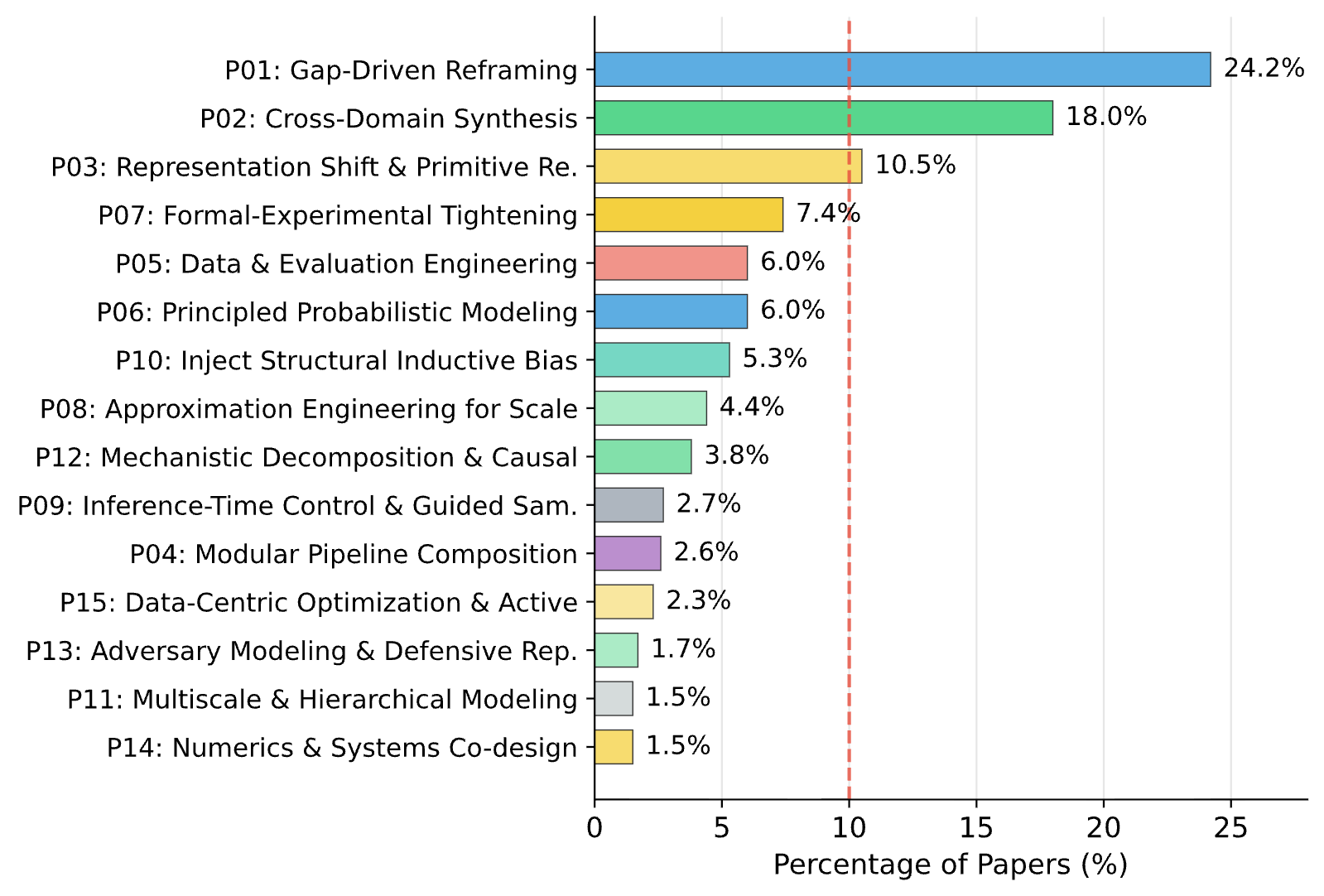
前三大思维模式
研究者诊断出特定的局限性,然后重新定义问题,使其映射到更合适的方法上。他们不只是解决问题,而是重塑问题。
突破往往来自从其他领域引入想法并设计兼容层。是借用和适配,而非从头发明。
改变问题的基本原语,如从像素到token、从网格到神经隐式函数,往往能简化下游的所有环节。
但真正有趣的发现在于组合。最成功的论文不只使用一种模式,而是将它们叠加:
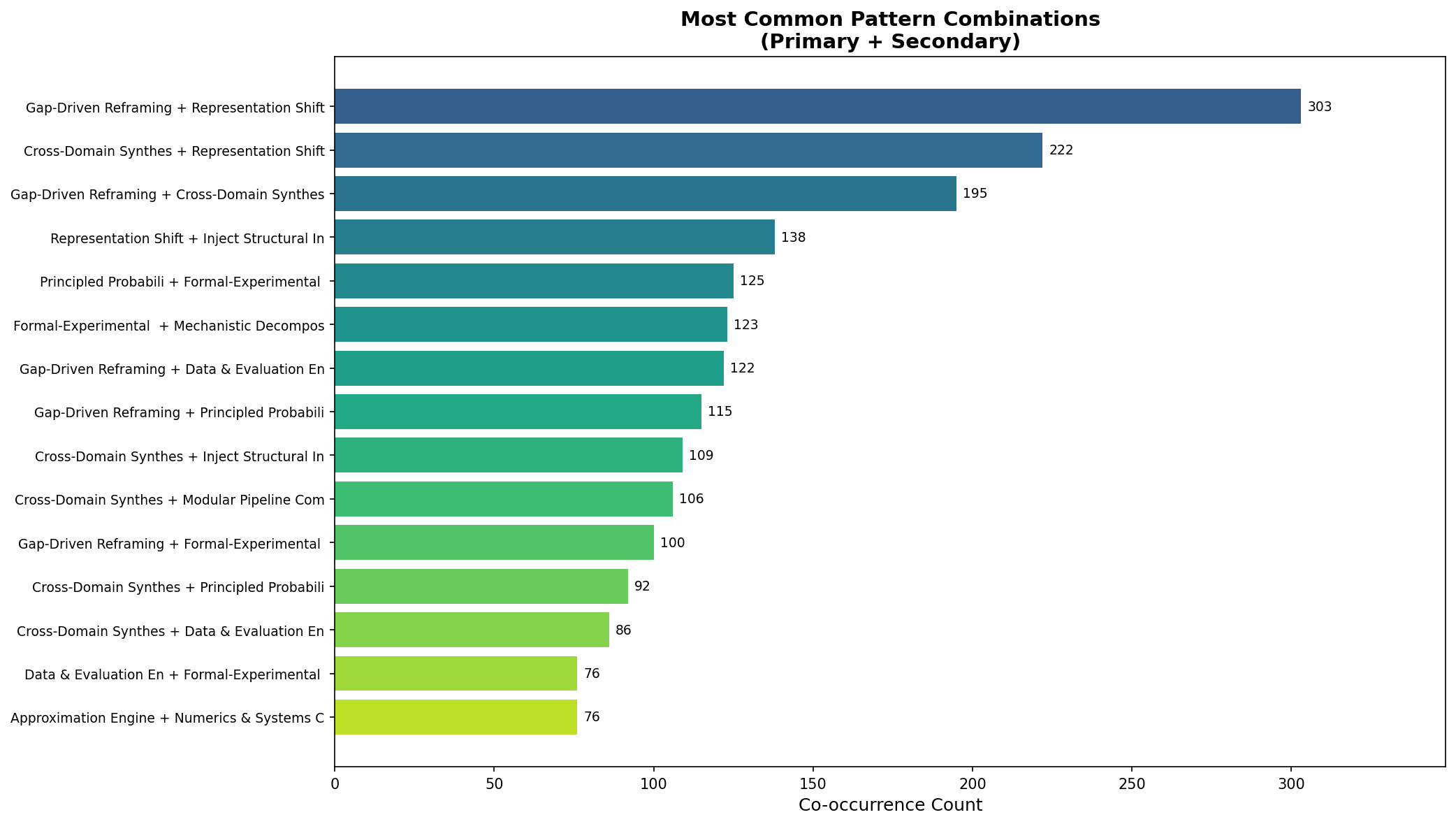
热门模式组合
诊断出局限性,然后引入新的表征来绕过它。
从其他领域借用机制,并修改其表征以适配你的领域。
识别缺失之处,然后在相邻领域寻找解决方案。
更多分析结果请参阅论文。
Sci-Reasoning: 解码AI研究创新的DNA
一个出于好奇心的项目最终催生了 Sci-Reasoning: 首个旨在捕捉高质量AI研究背后结构化学术综合推理的数据集。
使这一切成为可能的工作流,从爬取论文到提取脉络再到发现模式,仅用了 10天,从初始探索到论文投稿。这得益于下一代 Orchestra(即将发布),它能处理从构思到实验到写作的整个研究流水线。智能体接管了所有繁琐的工作,包括数据收集、处理、分析,同时智能化地管理整个研究项目。
数据集包含:
- 3,819篇来自 NeurIPS、ICML 和 ICLR (2023-2025) 的 Oral 和 Spotlight 论文
- 每篇论文的结构化脉络图
- 解释学术思维跳跃的综合叙述
- 支持定量分析的模式分类
训练AI科学家: 从模式到预测
让我真正兴奋的是: 这个数据集不仅仅是用来理解研究是如何发生的。它是AI研究智能体的训练数据。
我让智能体 评估了当前大语言模型预测研究方向的能力, 仅提供学术前驱论文作为输入。在 NeurIPS 2025 Oral 论文上测试,Gemini 2.5 Pro 达到了 49.35% 的 Hit@10 准确率,即近一半的情况下,十个生成的想法中有一个与实际发表的贡献相匹配。
| 模型 | Hit@10 (%) |
|---|---|
| Gemini 2.5 Pro | 49.35 |
| Claude Opus 4 | 42.86 |
| GPT-5.2 | 38.89 |
| Claude Sonnet 4 | 29.87 |
这并不完美,但已经非常了不起。它表明研究构思遵循着可学习的模式,我们现在可以系统性地研究这些模式,也有可能去传授这些模式。
创新即可学习的模式
创新并非魔法。它是高层次抽象上的模式匹配,结合深厚的领域知识和不懈的迭代。 通过将科学推理显式化,将隐含的"他们是怎么想到的?"转变为结构化的、可查询的数据,我们正在迈向一个AI系统不仅辅助研究,更能主动参与发现的未来。
当然,这其中存在局限性。创新通常只以最终成果的形式可见:一篇叙述清晰的精心打磨的论文。完整的思维轨迹,包括失败的尝试、反复的探索、被放弃的方向,几乎从未被记录下来。它锁在研究者的脑海中,散落在数月的 Slack 消息、白板照片和被删除的 LaTeX 文件里。捕捉一切几乎是不可能的。但我们可以捕捉最终成功的推理路径,即导向高质量成果的轨迹,而这正是 Sci-Reasoning 所提供的。