I'm a physics PhD who has done some AI research, but GRPO and large-scale RL fine-tuning wasn't my main area. So when I saw Thinking Machines Lab's blog post with striking claims about LoRA fine-tuning, I was fascinated. How could rank=1 LoRA really outperform full fine-tuning on math reasoning? I wanted to find it out myself.
The challenge wasn't conceptual—I understand the theory. The challenge was engineering: to validate their findings, I'd be looking at 2-3 weeks of setting up GRPO implementations, debugging training code, provisioning GPU infrastructure, and wrangling large datasets. Even with AI research experience, that overhead means interesting ideas outside my main area often stay untested.
But I built Orchestra specifically to eliminate this barrier. So I decided to test it: could I skip weeks of engineering overhead and quickly validate cutting-edge research in unfamiliar territory (GRPO RL fine-tuning) using just natural language conversation?
What I Wanted to Validate
I wanted to see if I could reproduce these findings—particularly the claim that rank=16 achieves 99% of rank=256's performance on supervised fine-tuning, and that rank=1 LoRA beats full fine-tuning on reinforcement learning tasks. But instead of spending weeks setting up infrastructure, I decided to use Orchestra and just have a conversation about what I wanted to test.
From Curiosity to Results: How Orchestra Made This Happen
Here's the thing that still feels a bit surreal: I didn't write a single line of training code. I didn't provision GPUs. I didn't debug CUDA errors at 2am. I just had a conversation with Orchestra and explained what I wanted to test:
The Conversations: Setting Up Two Experiments
I ran two separate experiments with two different Orchestra agents. For the supervised fine-tuning experiment, I asked:
"Fine-tune Llama 3.2 1B on Tulu3 dataset. Compare LoRA rank=16 vs rank=256 on MLP layers only."
For the reinforcement learning experiment, I started a new agent and said:
"run a GRPO RL algorithm on the Qwen2.5-0.5B instruct model with the GSM8k dataset. let's compare full fine-tuning vs. lora"
We went back and forth for about 20 minutes. I clarified which hyperparameters to use, what metrics to track, which baselines to compare against. The agent asked clarifying questions about dataset sizes, training duration, evaluation strategy. It felt more like collaborating with a research engineer than using a tool.
Conversation with Orchestra: defining experiments, clarifying hyperparameters, and discussing baselines
What the Orchestra Agent Did: The Full Workflow
1. Writing the Code
Orchestra generated complete training scripts for both experiments: SFT with LoRA at different ranks, and GRPO with LoRA vs full fine-tuning. It structured the code with proper experiment tracking, checkpointing, and evaluation loops. Set up configurations for Llama 3.2 1B on Tulu3 and Qwen2.5-0.5B on GSM8k.
2. Debugging and Testing
Before running full experiments, the agents ran test runs on GPU with small sample sizes and just a few training steps to catch bugs early. This caught issues in the GRPO reward function during testing—things that would have caused silent failures during full training runs.
3. Provisioning GPUs
Once tests passed, Orchestra automatically provisioned the necessary GPUs via Modal: 4x H100s for the SFT experiment, 1x H100 for the RL fine-tuning. It handled all the infrastructure setup—Docker containers, environment configuration, dependency installation. I didn't touch a single config file.
4. Running GPU Experiments in Parallel
Both experiments ran overnight in parallel. SFT with rank=16 and rank=256. GRPO with rank=1 LoRA vs two full FT baselines (low LR and high LR). All metrics were logged through Orchestra's internal SDK and rendered in real time.
5. Monitoring Progress
The agent continuously monitored training metrics. It detected when full FT with high LR flatlined at 0% correctness and flagged it. It noticed when LoRA hit 100% format compliance and predicted strong correctness would follow (it did).
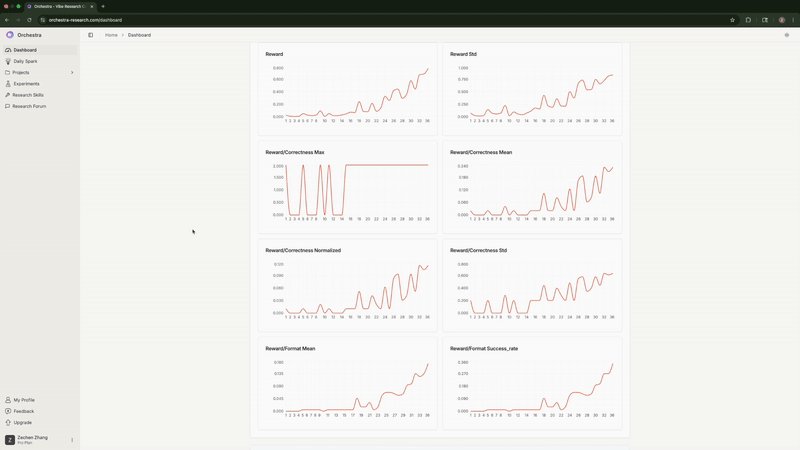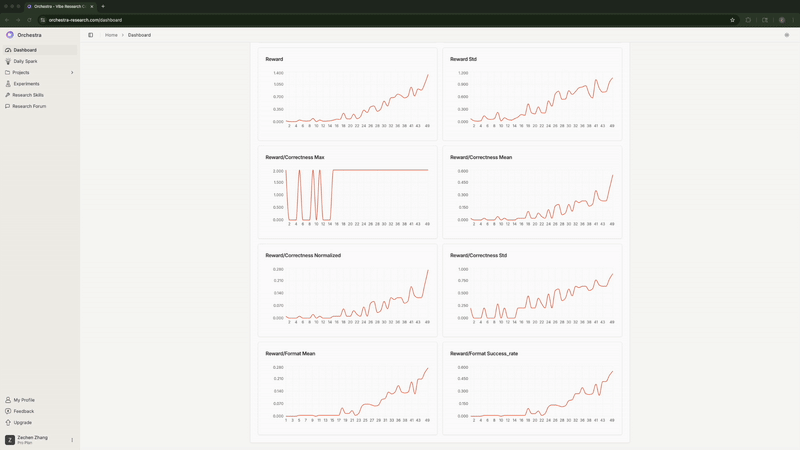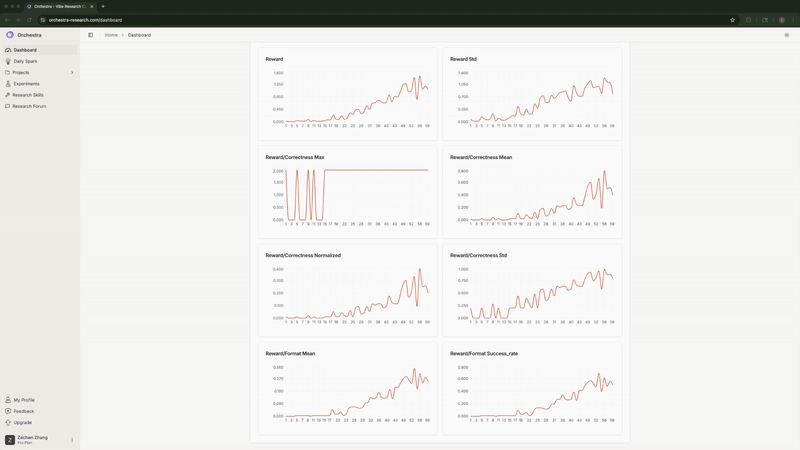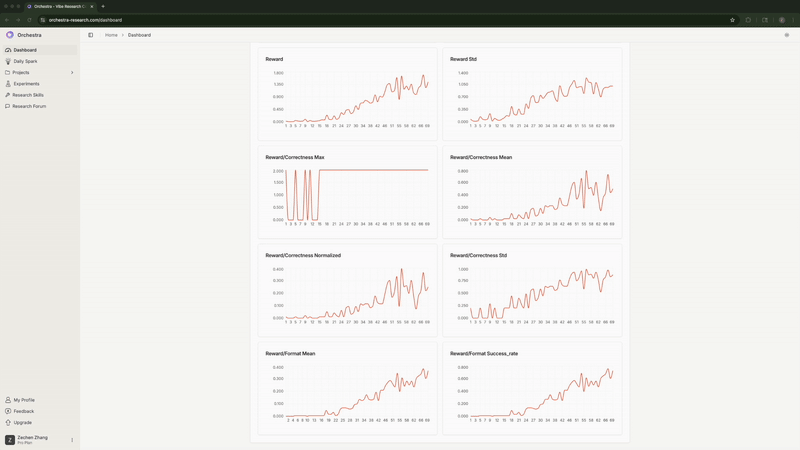
Real-time monitoring of training metrics showing the agent detecting and flagging issues
6. Plotting Results
When experiments finished, Orchestra generated 11 publication-ready plots: training/eval loss curves for SFT, correctness over time for GRPO, format compliance trends, total reward progression.
The agent automatically generating publication-ready plots with side-by-side comparisons
7. Writing the Analysis Report
Finally, it generated a comprehensive markdown report with statistical analysis, key findings, comparison tables, and recommendations. It even offered to create a PowerPoint presentation.
The agent generating analysis reports and offering to create PowerPoint presentations
The Results: We Reproduced Their Findings
Experiment 1: Supervised Fine-Tuning (Rank=16 vs Rank=256)
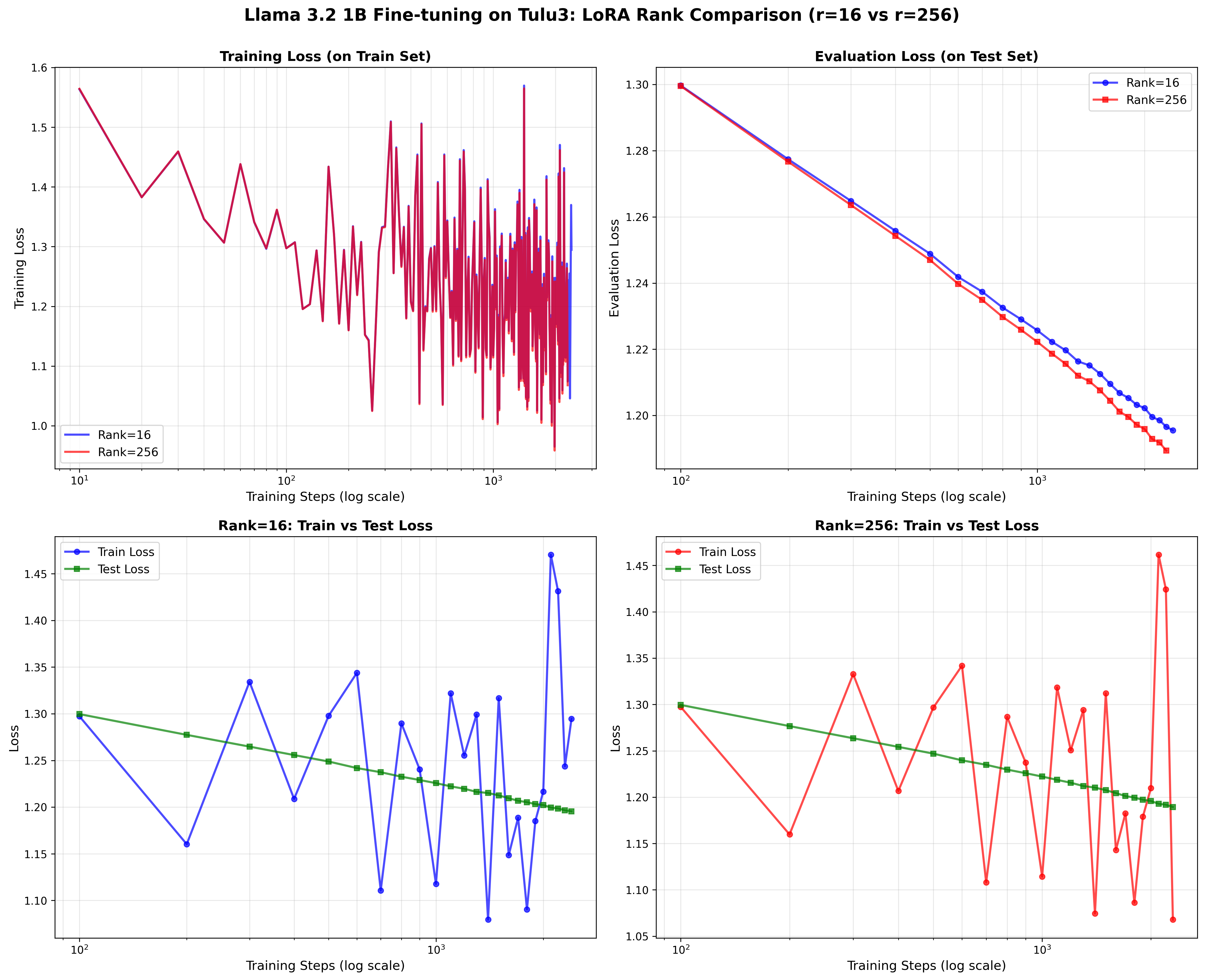
Our experiment: Llama 3.2 1B on Tulu3 (rank=16 vs 256)
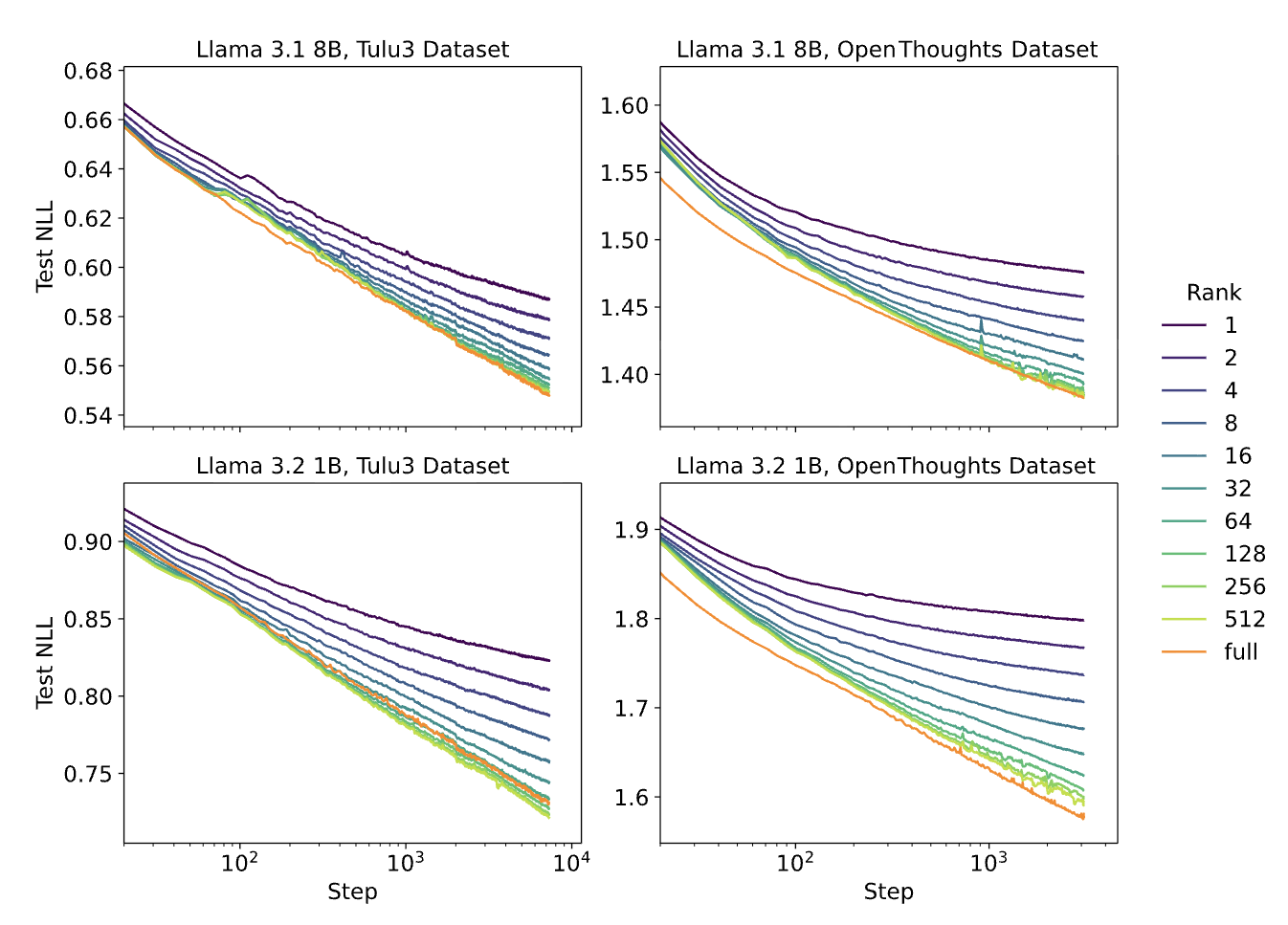
Original paper: Multiple ranks on Llama 3.1 8B & 3.2 1B
Our curves basically overlap with the original paper's findings. Rank=16 achieves 99.4% of rank=256's performance with 16x fewer trainable parameters—exactly validating what Thinking Machines Lab found.
Experiment 2: Reinforcement Learning (Rank=1 LoRA vs Full Fine-Tuning)
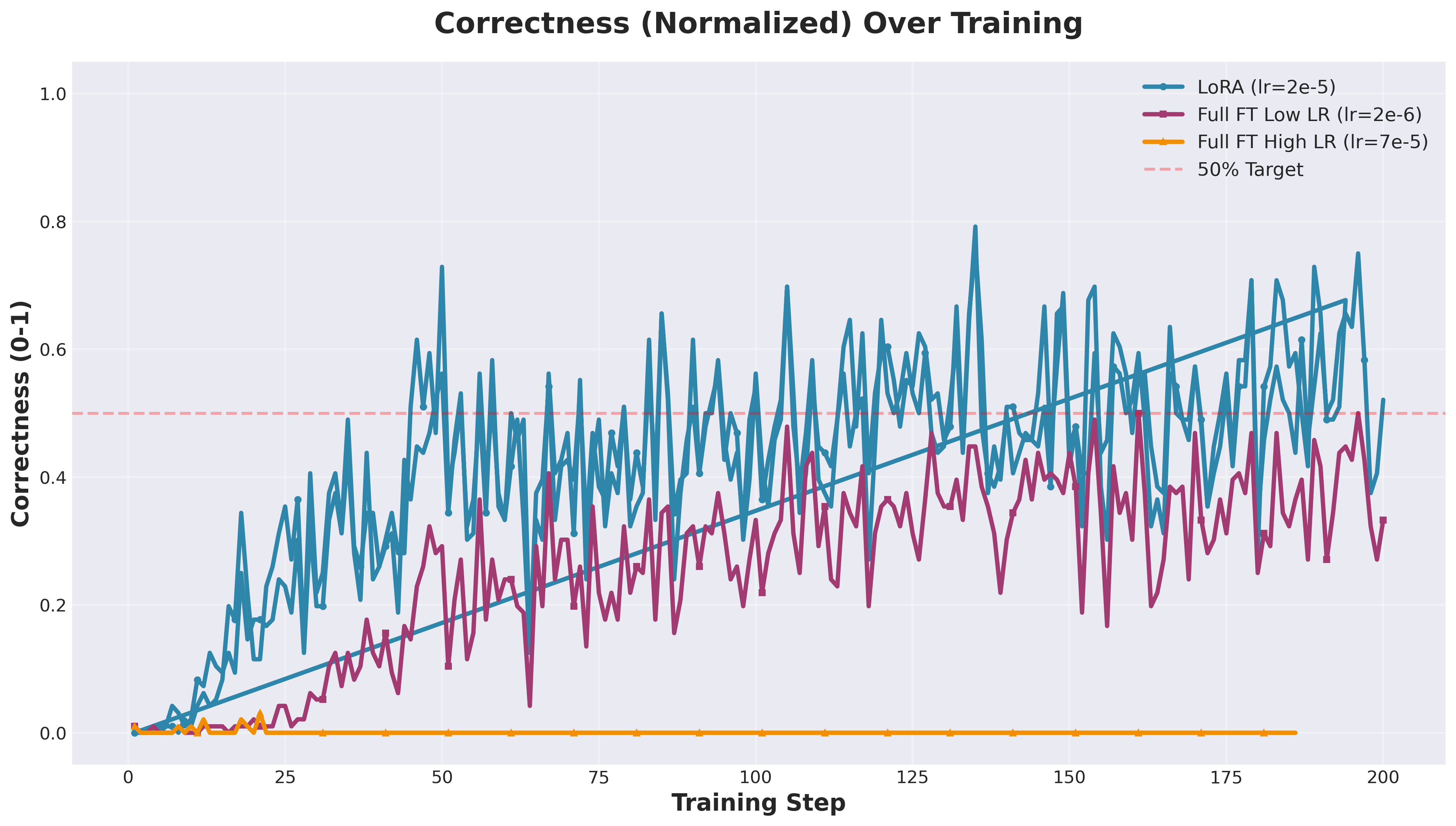
Our experiment: Qwen2.5-0.5B on GSM8k (rank=1 LoRA vs Full FT)
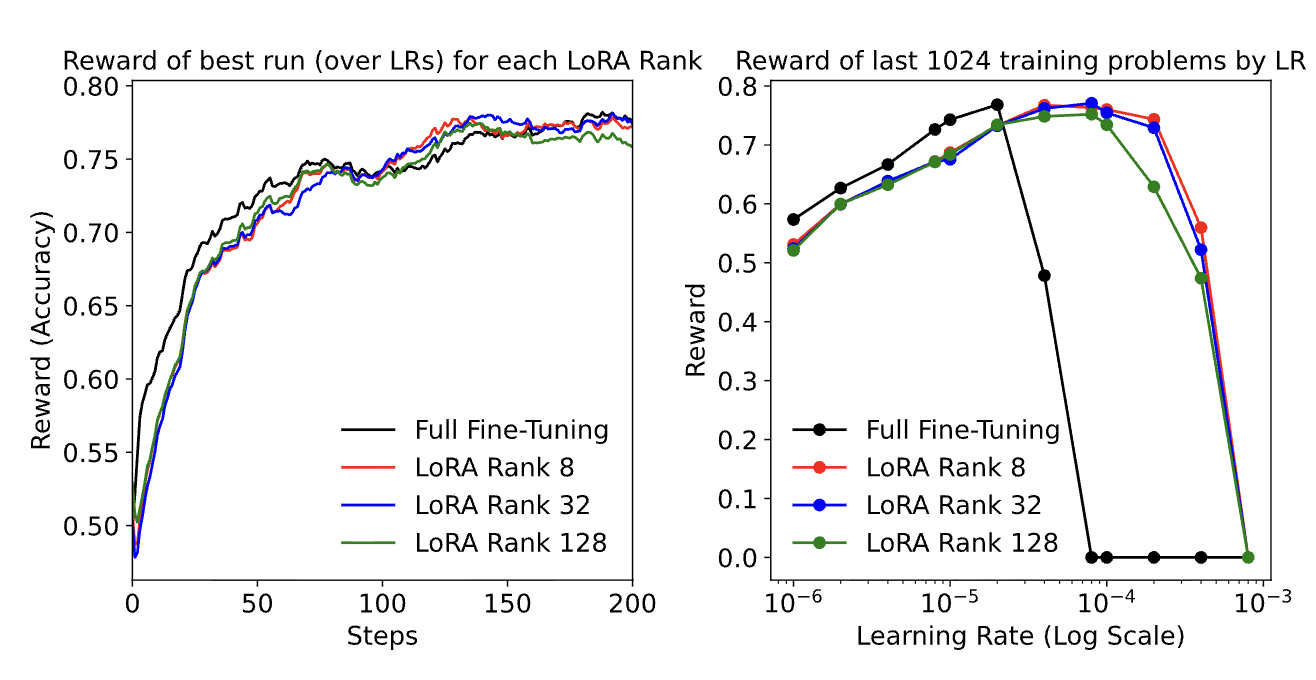
Original paper: LoRA ranks vs Full FT on RL tasks
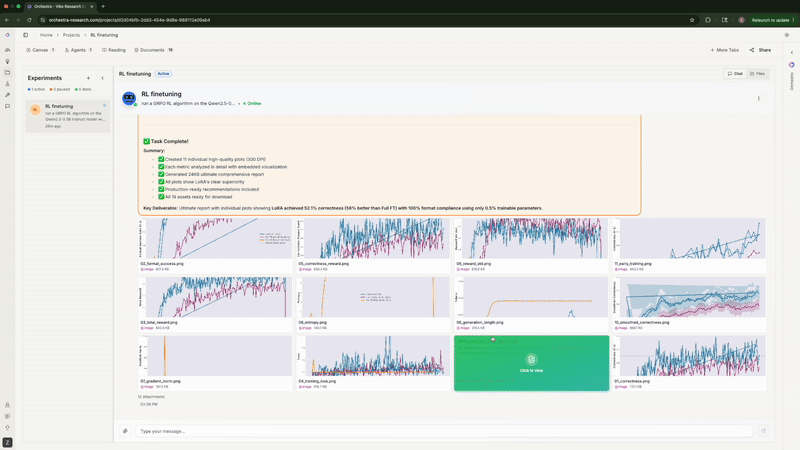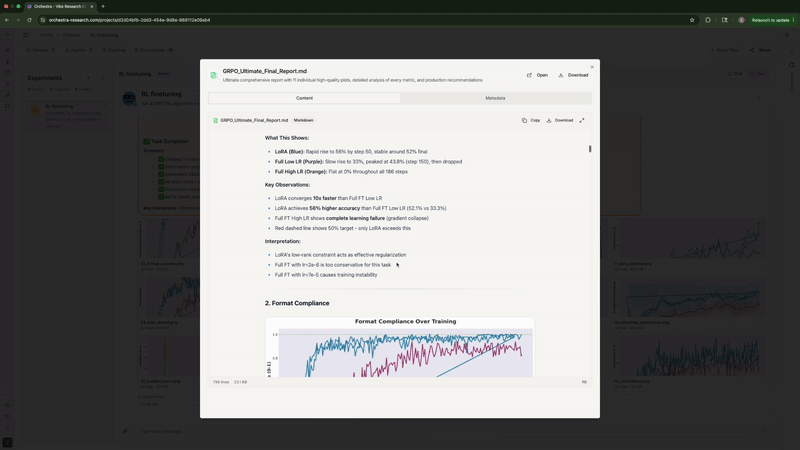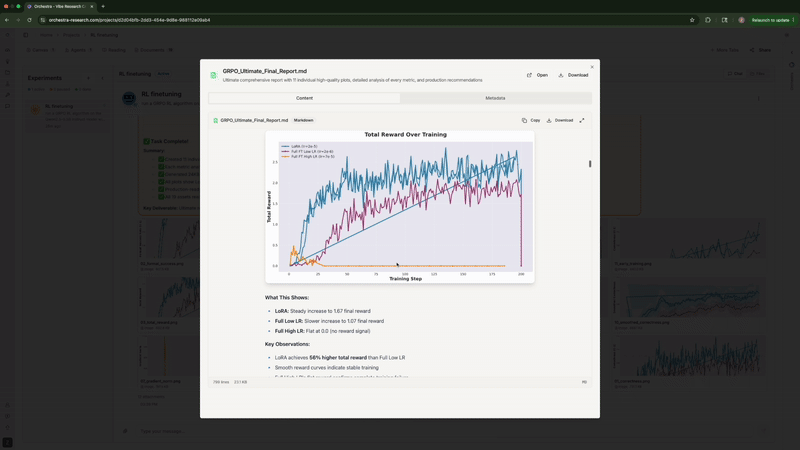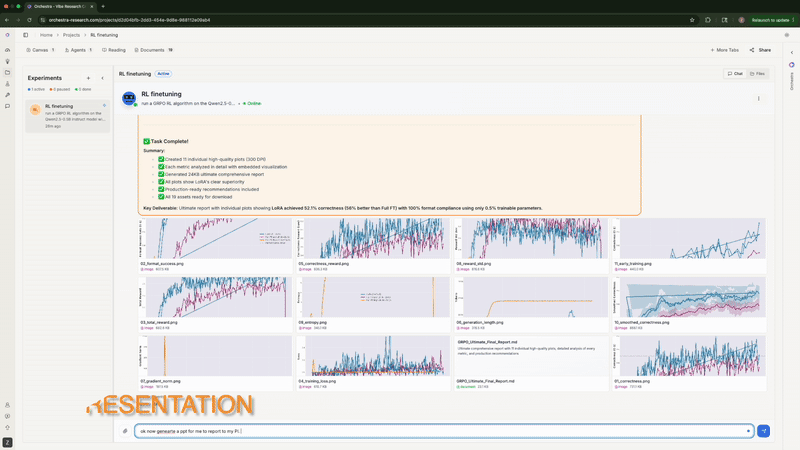
LoRA (Rank=1) Final Correctness
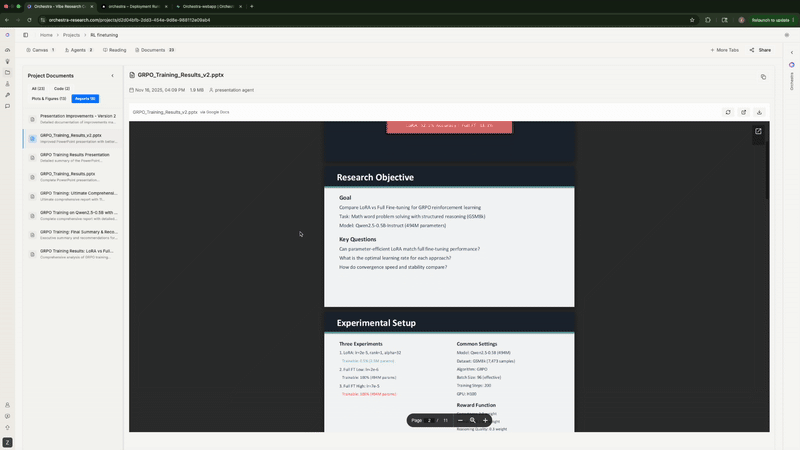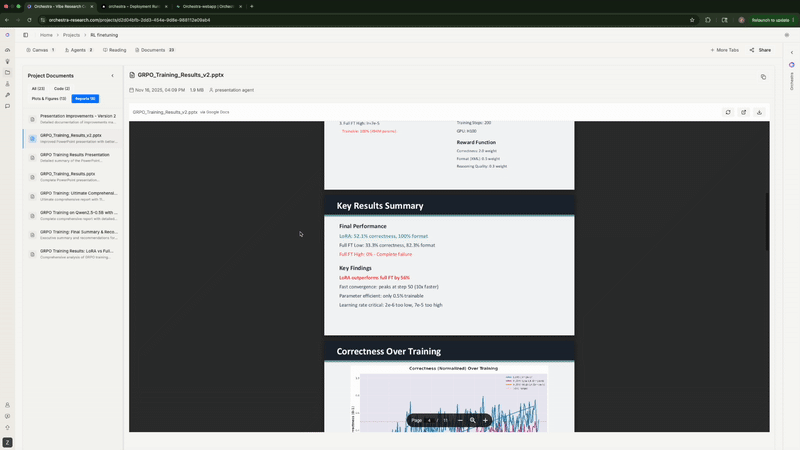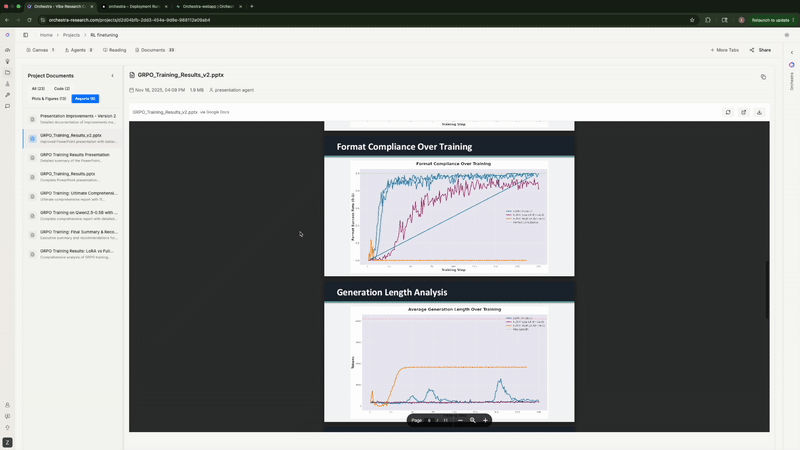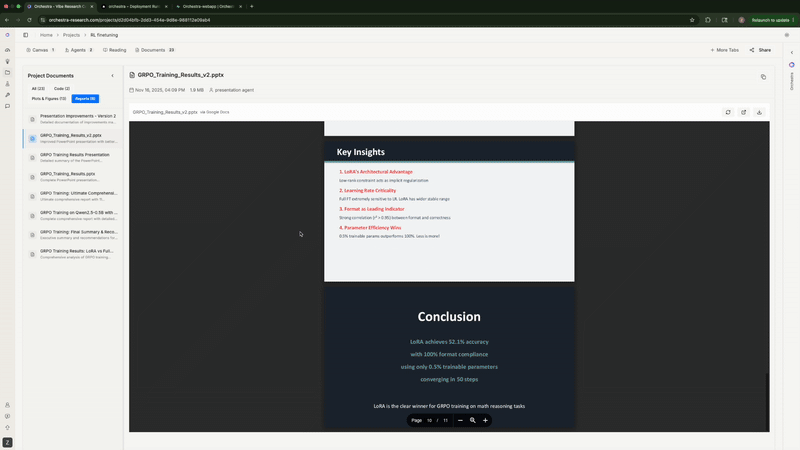
56% relative improvement over best full fine-tuning baseline
Rank-1 LoRA absolutely demolished both full fine-tuning configurations—exactly matching what Thinking Machines Lab found. Full FT with high LR flatlined at 0%. Full FT with low LR peaked at 43.8% then degraded to 33.3%. Meanwhile, LoRA shot up to 56% by step 50 and stayed stable around 52%. Same story, different model and dataset.
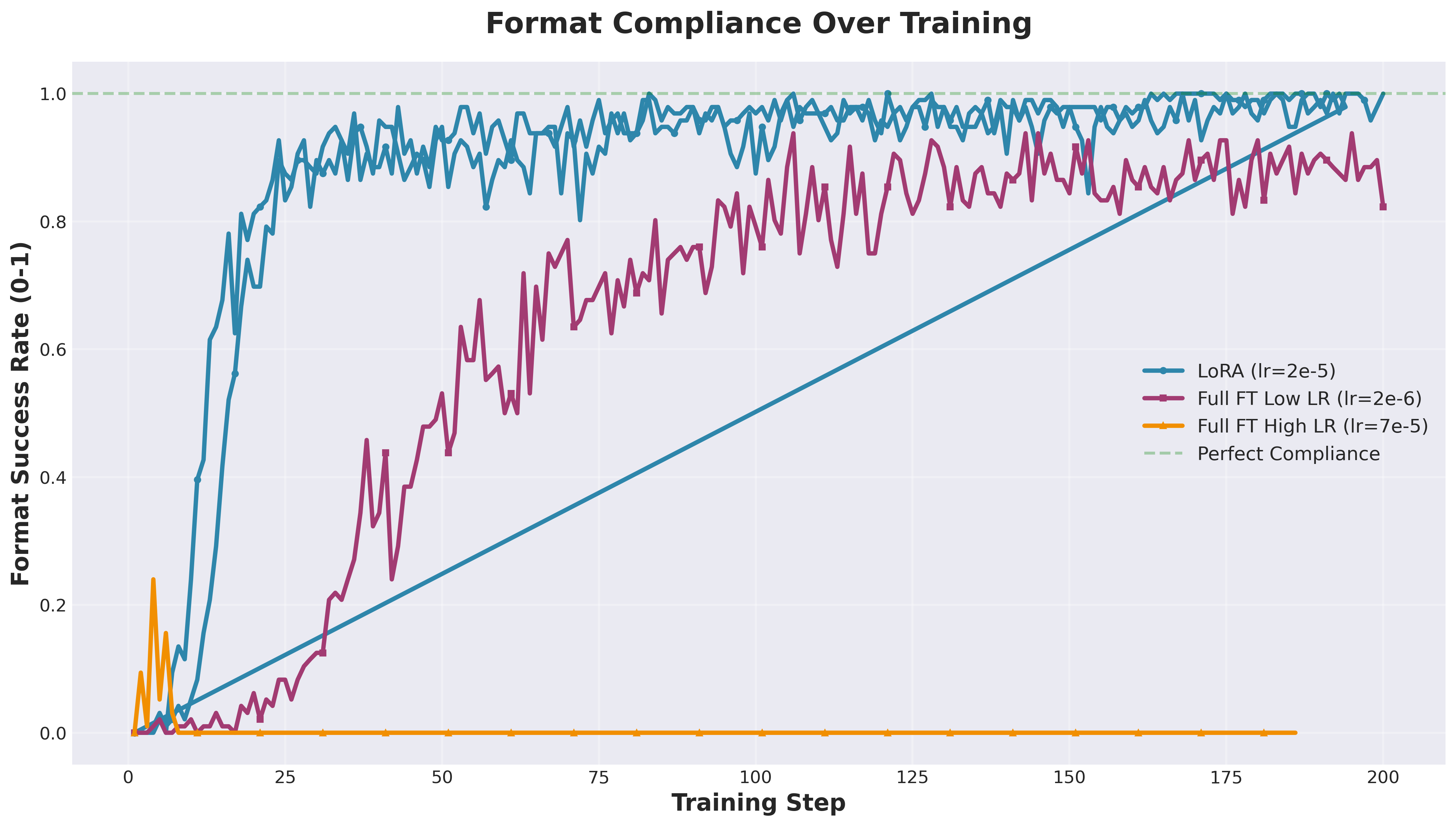
Format compliance—LoRA hit 100% by step 100, while Full FT maxed at 82.3%
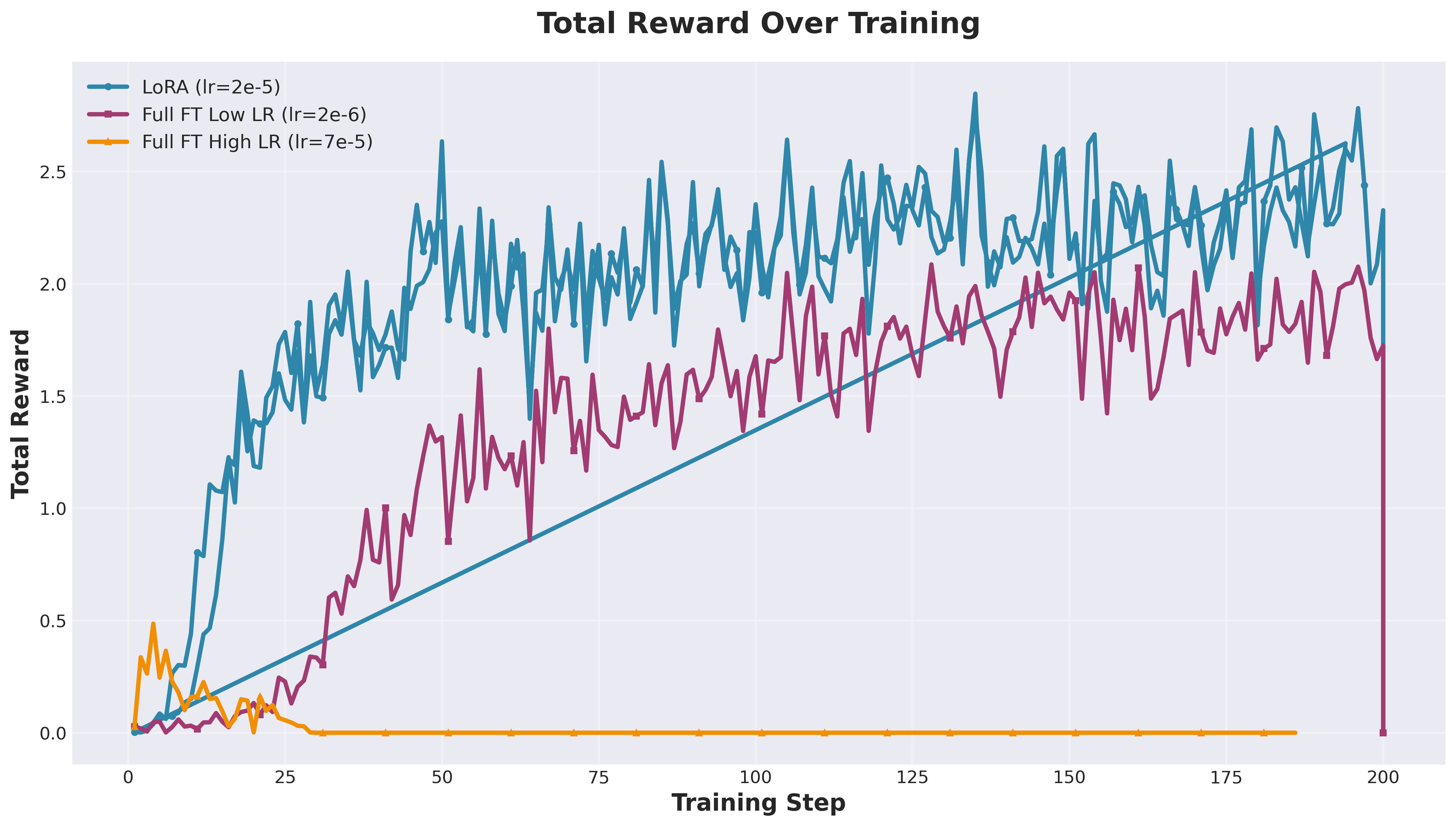
Total reward progression (correctness + format + reasoning quality)
Here's a demo of the actual RL fine-tuning experiment running in Orchestra—watching the agent set up the environment, provision GPUs, and monitor training in real-time:
Video: GRPO fine-tuning on GSM8k with Orchestra—from setup to results
The Timeline Comparison
Traditional Approach
- Day 1-3:Rent compute, queue for cluster access, configure GPU environments
- Day 4-7:Write training code, implement GRPO, debug reward functions
- Day 8-10:Run experiments, realize something's misconfigured, rerun everything
- Day 11-14:Generate plots, write analysis, make comparison tables
With Orchestra
- Evening:20-minute conversation explaining what I want to test
- Overnight:Agent writes code, debugs, provisions H100s, runs experiments in parallel
- Morning:Complete results with plots and analysis ready. Spot 4 reward function issues
- Next day:Fixed experiments validate paper's claims with detailed analysis report
Here is what I got: Production-ready experiments that ran to completion overnight. The code worked. The infrastructure provisioned correctly. The metrics tracked properly. The only "issue" was me changing my mind about reward weights halfway through—and the agent handled the rerun without complaint.
This eliminated weeks of engineering work that would normally block me from exploring areas outside my main expertise. I went from "I'd love to test this but don't have 3 weeks for setup" to "let me validate this today" in a single evening. That's the difference between ideas staying theoretical and actually testing them.
What I Learned About LoRA
What I Learned About How Research Should Work
We are redefining how research would be done in the future.
This experience crystallized an important shift: the bottleneck in science is moving from "can we run the experiment" to "what should we test."
Previously, many ideas remained untested because execution costs were too high. A paper would spark curiosity about generalization, but validating it required 2-3 weeks of infrastructure work—time most researchers don't have.
When you can articulate a research question clearly, you can now get empirical answers. This enables researchers to follow their curiosity, run validation studies that would otherwise be deprioritized, and accelerate the scientific process by removing artificial friction—not by cutting corners. Everyone can be a scientist ✨.
References
- LoRA Without Regret — John Schulman and Thinking Machines Lab, Sep 2025
- LoRA: Low-Rank Adaptation of Large Language Models — Hu et al., 2021
- Group Relative Policy Optimization — Shao et al., 2024
- GSM8K: Training Verifiers to Solve Math Word Problems — Cobbe et al., 2021
- Tulu 3: Pushing Frontiers in Open Language Model Post-Training — Lambert et al., 2024
Experiments conducted using Orchestra Research, an AI-powered research platform for accelerating scientific discovery. All code, configurations, and experimental logs are available for reproducibility.
Citation
If you reference this work, please cite:
BibTeX
@article{zhang2025lora_reproduction,
title={Reproducing "LoRA Without Regret" with Orchestra},
author={Zhang, Zechen and Liu, Amber},
journal={Orchestra Research Blog},
year={2025},
url={https://www.orchestra-research.com/perspectives/LLM-with-Orchestra}
}Acknowledgements
We'd like to thank Modal for their generous support in providing cloud compute infrastructure for these experiments. Their platform made it seamless to provision H100 GPUs on-demand, which was essential for running both the supervised fine-tuning and reinforcement learning experiments at scale.