我是一名物理学博士, 也做过一些 AI 研究, 但 GRPO 和大规模 RL 微调并非我的主要方向。所以当我看到 Thinking Machines Lab 的博客文章 中关于 LoRA 微调的惊人结论时, 我非常着迷。rank=1 的 LoRA 怎么可能在数学推理任务上超越全参数微调? 我想亲自验证。
挑战不在于概念理解, 我了解背后的理论。真正的挑战在于工程实现: 要验证他们的发现, 我需要花 2-3 周时间搭建 GRPO 实现、调试训练代码、 配置 GPU 基础设施以及处理大规模数据集。即使有 AI 研究经验, 这些工程开销也意味着主研究方向之外的有趣想法往往无法付诸实践。
但我创建 Orchestra 正是为了消除这个障碍。所以我决定做个测试: 我能否跳过数周的工程准备, 仅通过自然语言对话, 快速验证自己 不熟悉领域(GRPO RL 微调)的前沿研究?
我想验证的内容
我想验证这些发现, 特别是 rank=16 能达到 rank=256 99% 性能的说法(在监督微调上), 以及 rank=1 LoRA 在强化学习任务上 优于全参数微调的结论。但我不想花几周搭建基础设施, 而是决定 使用 Orchestra, 通过对话来描述我想测试的内容。
从好奇到结果: Orchestra 是如何实现的
有一件事至今让我觉得不太真实: 我没有写一行训练代码, 没有配置 GPU, 也没有在凌晨两点调试 CUDA 错误。我只是和 Orchestra 进行了一次对话, 说明了我想测试什么:
对话过程: 设计两个实验
我用两个不同的 Orchestra Agent 分别进行了两个实验。对于监督微调实验, 我这样说:
"对 Llama 3.2 1B 在 Tulu3 数据集上进行微调。比较仅在 MLP 层上使用 LoRA rank=16 和 rank=256 的效果。"
对于强化学习实验, 我启动了一个新的 Agent 并说:
"在 Qwen2.5-0.5B instruct 模型上运行 GRPO RL 算法, 使用 GSM8k 数据集。比较全参数微调和 LoRA。"
我们来回交流了大约 20 分钟。我说明了使用哪些超参数、跟踪哪些指标、 与哪些基线进行比较。Agent 会询问关于数据集大小、训练时长、 评估策略等澄清性问题。这种感觉更像是在和一位研究工程师协作, 而不是在使用一个工具。
与 Orchestra 的对话: 定义实验、确认超参数、讨论基线
Orchestra Agent 做了什么: 完整工作流程
1. 编写代码
Orchestra 为两个实验生成了完整的训练脚本: 不同 rank 的 SFT LoRA, 以及 LoRA 对比全参数微调的 GRPO。它合理地组织了代码结构, 包含实验追踪、检查点保存和评估循环。为 Llama 3.2 1B (Tulu3 数据集) 和 Qwen2.5-0.5B (GSM8k 数据集) 分别配置了实验。
2. 调试与测试
在运行完整实验之前, Agent 先在 GPU 上用小样本和少量训练步数 进行了测试, 以尽早发现问题。这在测试阶段就捕获了 GRPO 奖励函数中的问题, 如果拖到正式训练中才发现, 将会导致 难以察觉的失败。
3. 配置 GPU
测试通过后, Orchestra 通过 Modal 自动配置了所需的 GPU: SFT 实验使用 4 块 H100, RL 微调使用 1 块 H100。它处理了所有 基础设施搭建, 包括 Docker 容器、环境配置和依赖安装。 我没有碰过任何一个配置文件。
4. 并行运行 GPU 实验
两个实验一夜之间并行运行。SFT 实验对比 rank=16 和 rank=256。 GRPO 实验对比 rank=1 LoRA 和两个全参数微调基线(低学习率和高学习率)。 所有指标通过 Orchestra 的内部 SDK 记录, 并实时渲染。
5. 监控进度
Agent 持续监控训练指标。它发现高学习率的全参数微调 正确率停滞在 0% 并发出了警报。它注意到 LoRA 的格式合规率 达到 100%, 并预测正确率也将随之提升(事实确实如此)。
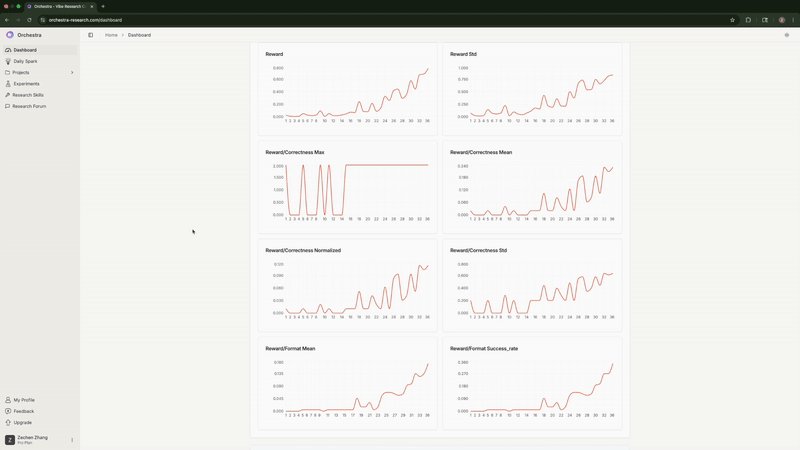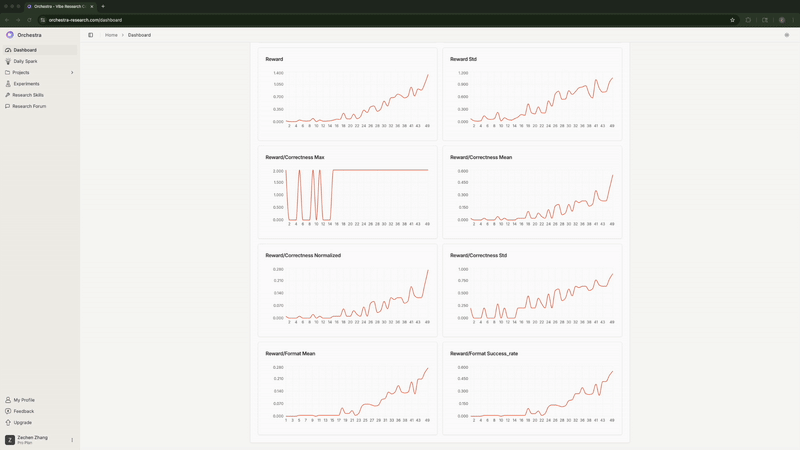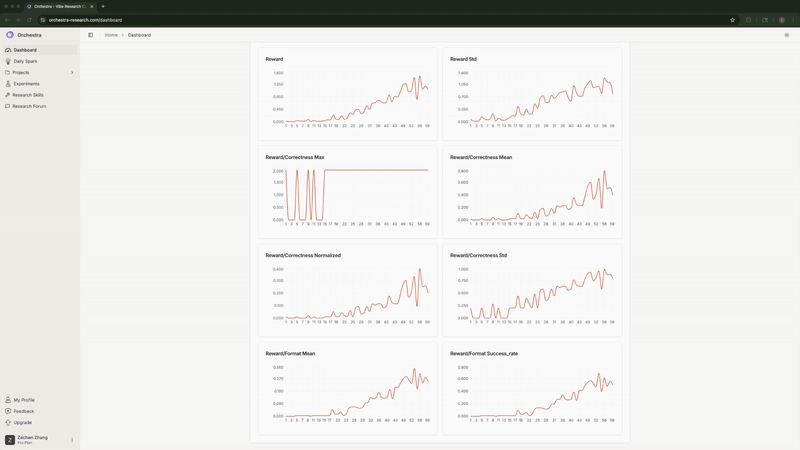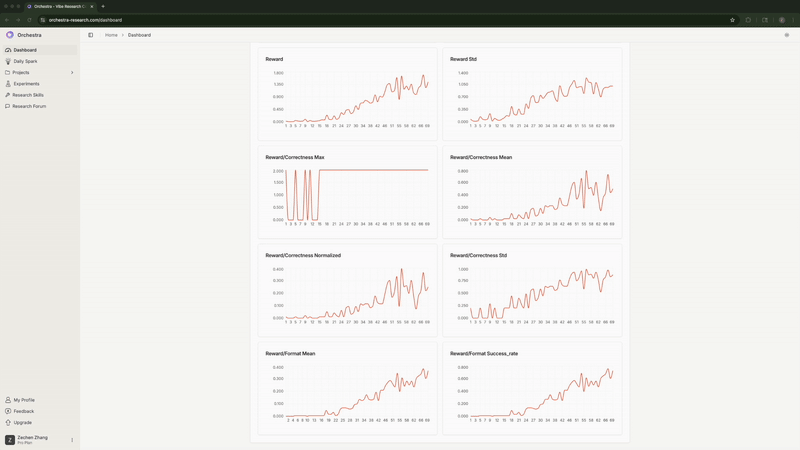
实时监控训练指标, Agent 自动检测并标记异常情况
6. 绘制结果图表
实验完成后, Orchestra 生成了 11 张可直接用于论文发表的图表: SFT 的训练/评估损失曲线, GRPO 的正确率随时间变化, 格式合规率趋势, 总奖励进展等。
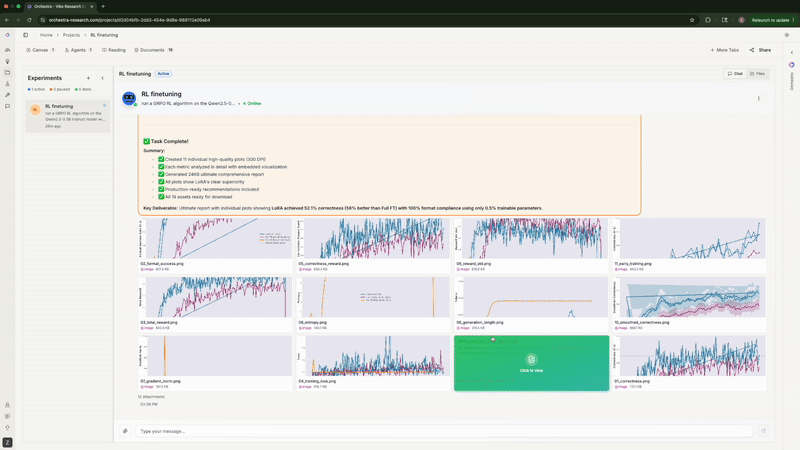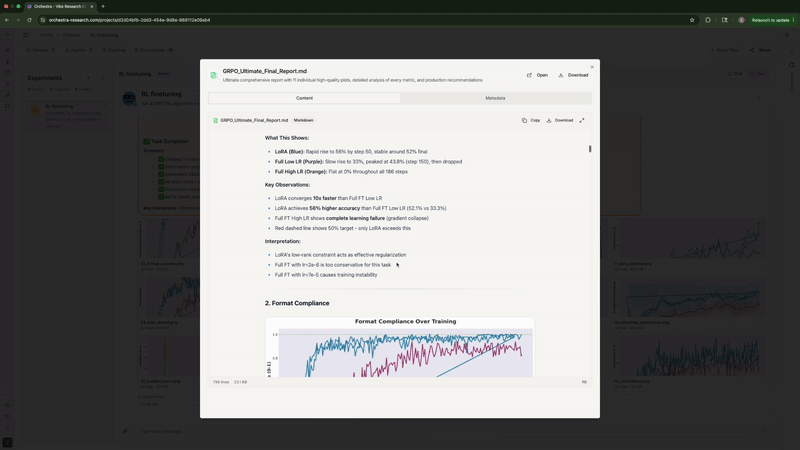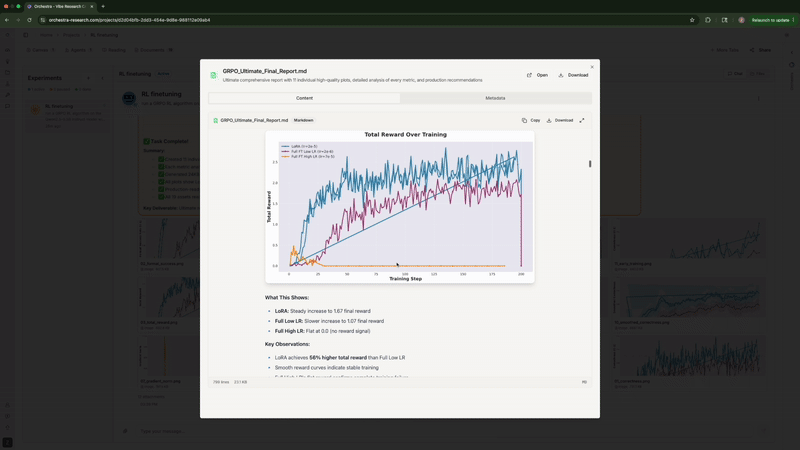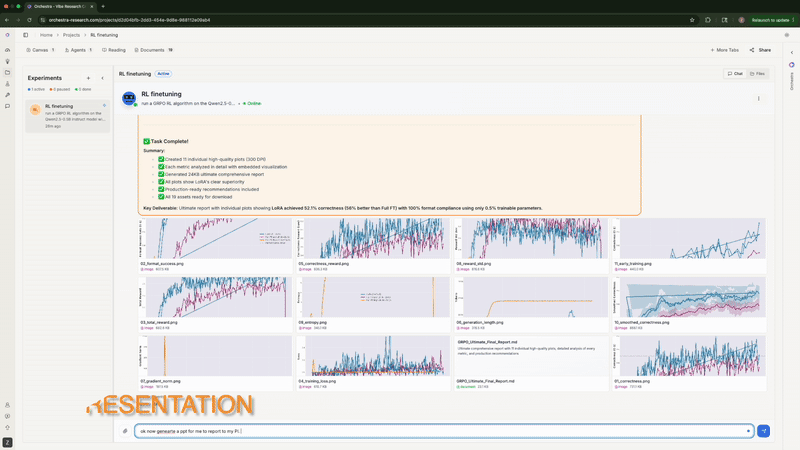
Agent 自动生成可发表的图表, 并进行并排对比
7. 撰写分析报告
最后, 它生成了一份完整的 Markdown 报告, 包含统计分析、 核心发现、对比表格和建议。它甚至主动提出可以制作 PowerPoint 演示文稿。
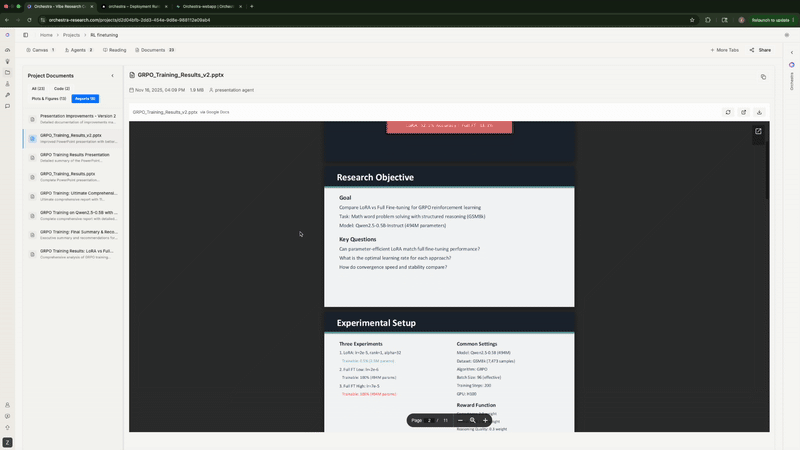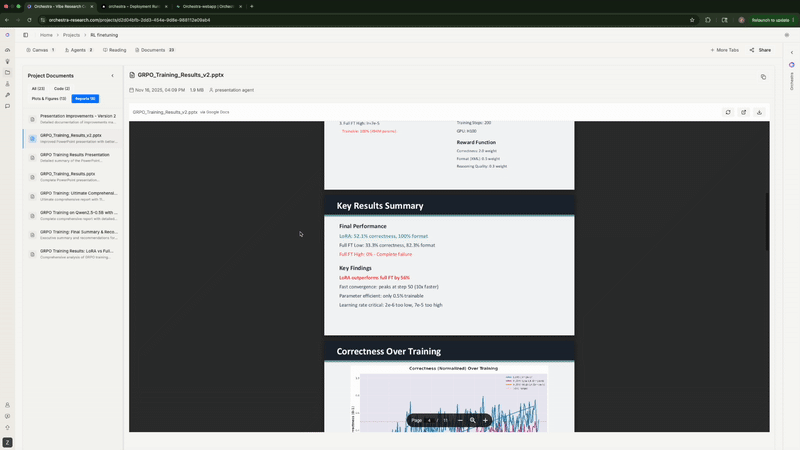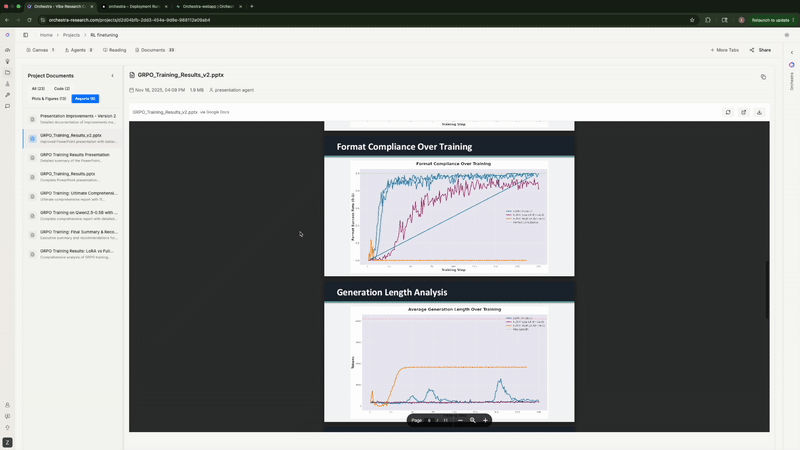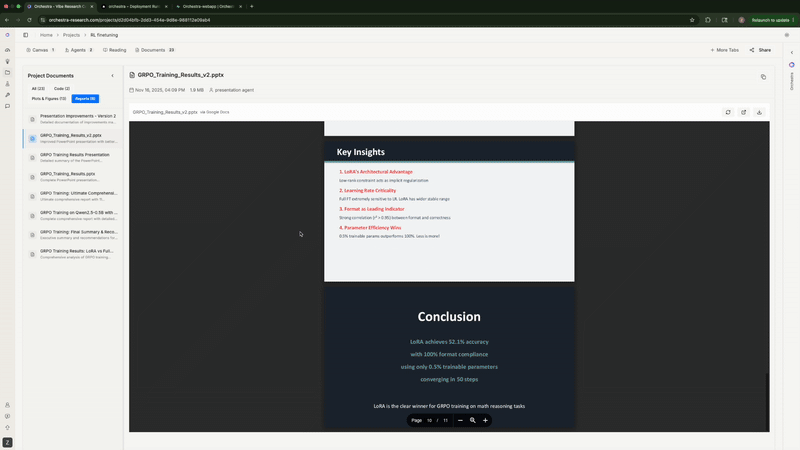
Agent 生成分析报告, 并主动提出制作 PowerPoint 演示文稿
实验结果: 我们复现了他们的发现
实验一: 监督微调 (Rank=16 vs Rank=256)
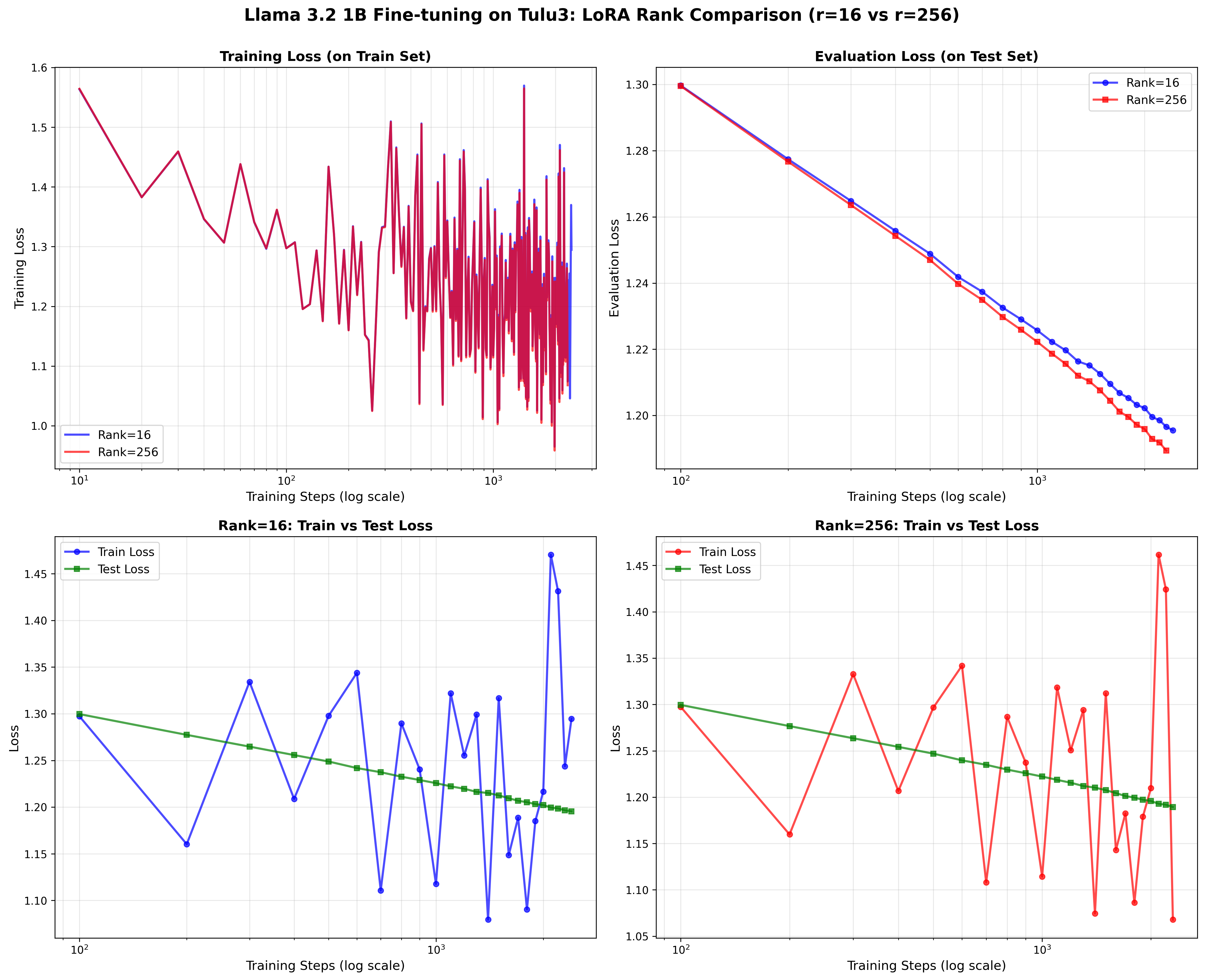
我们的实验: Llama 3.2 1B 在 Tulu3 上 (rank=16 vs 256)
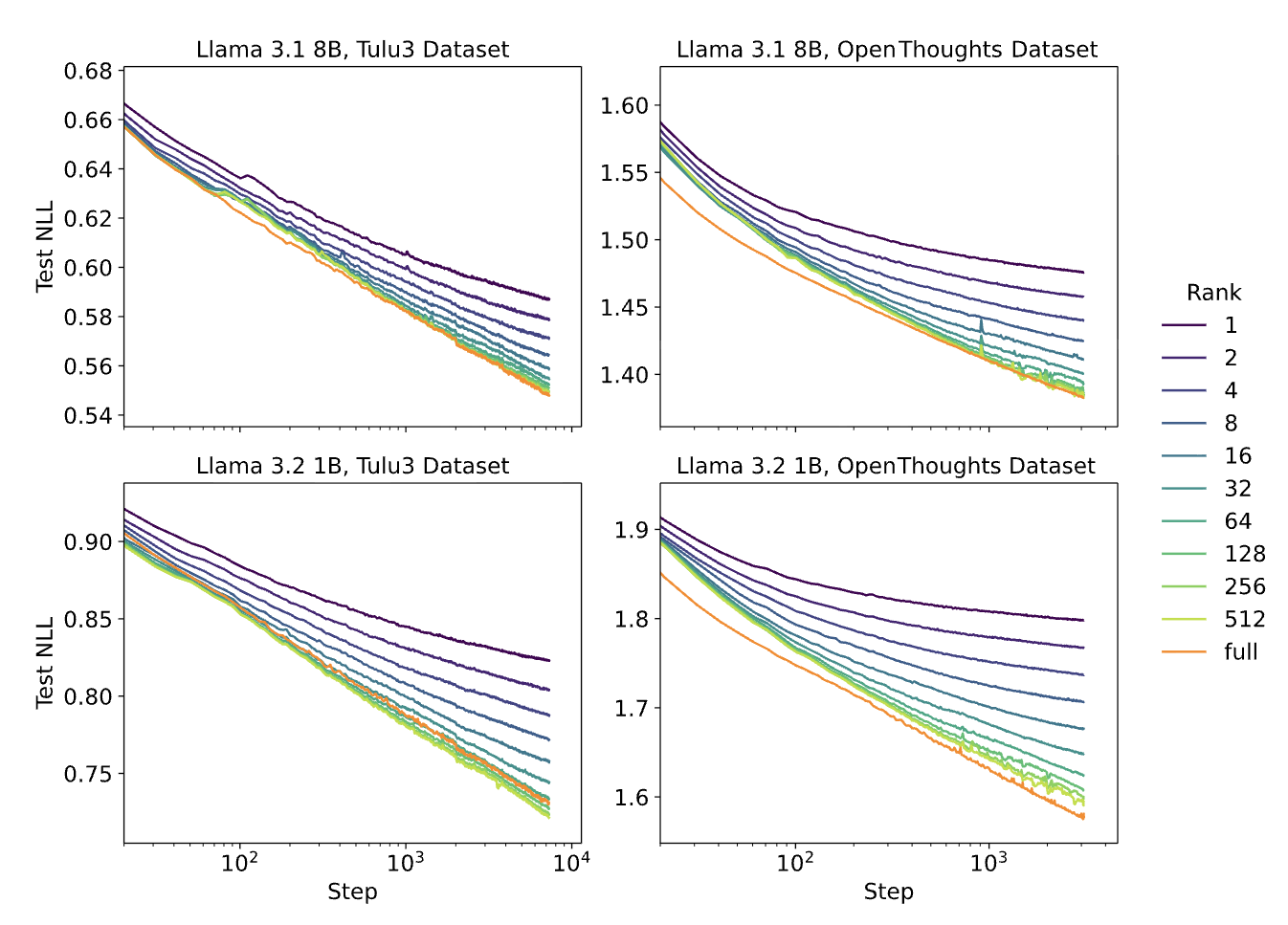
原论文: 在 Llama 3.1 8B 和 3.2 1B 上测试多种 rank
我们的曲线基本与原论文的结果重叠。Rank=16 以 16 倍更少的 可训练参数达到了 rank=256 99.4% 的性能, 完全验证了 Thinking Machines Lab 的发现。
实验二: 强化学习 (Rank=1 LoRA vs 全参数微调)
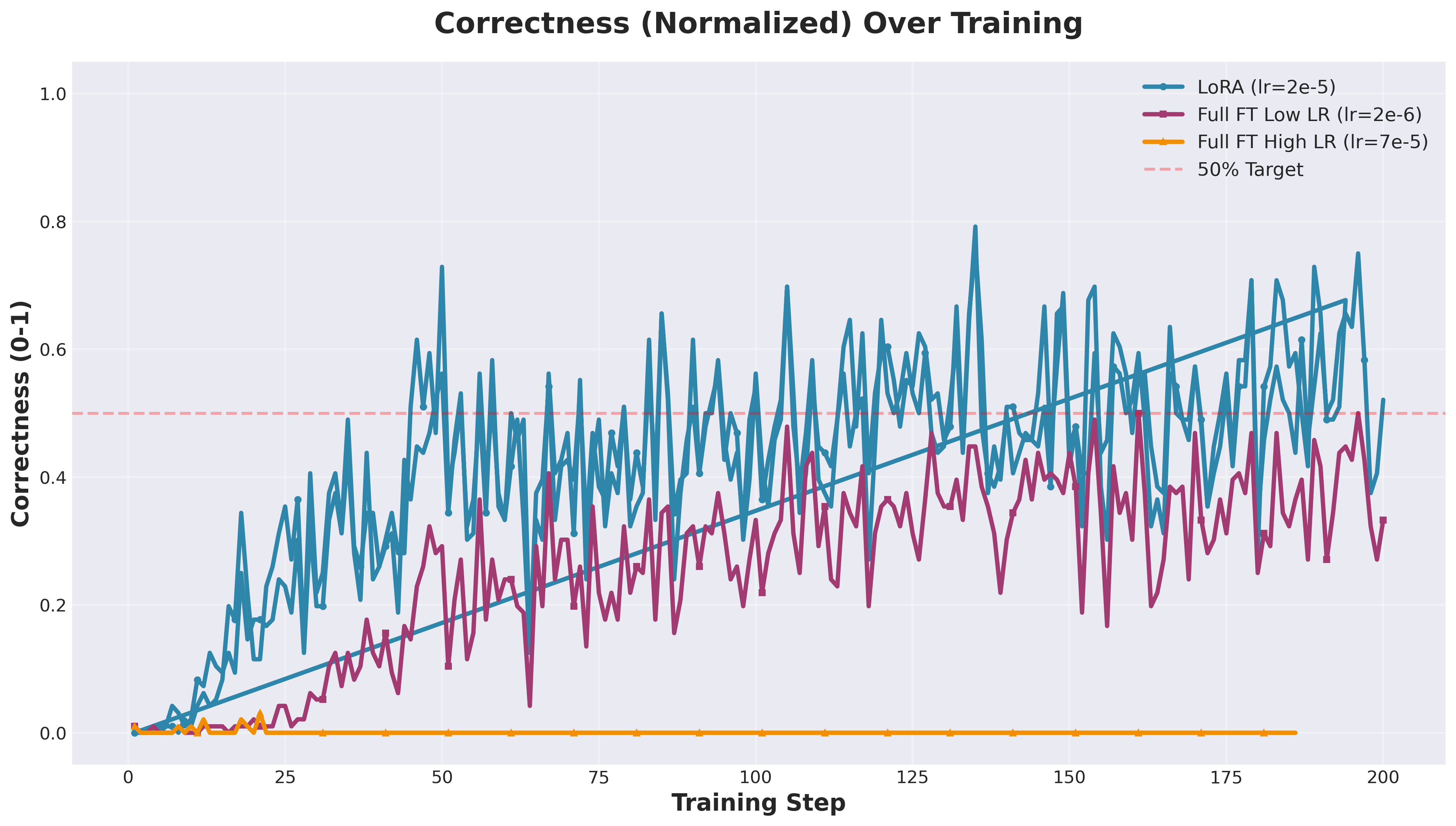
我们的实验: Qwen2.5-0.5B 在 GSM8k 上 (rank=1 LoRA vs 全参数微调)
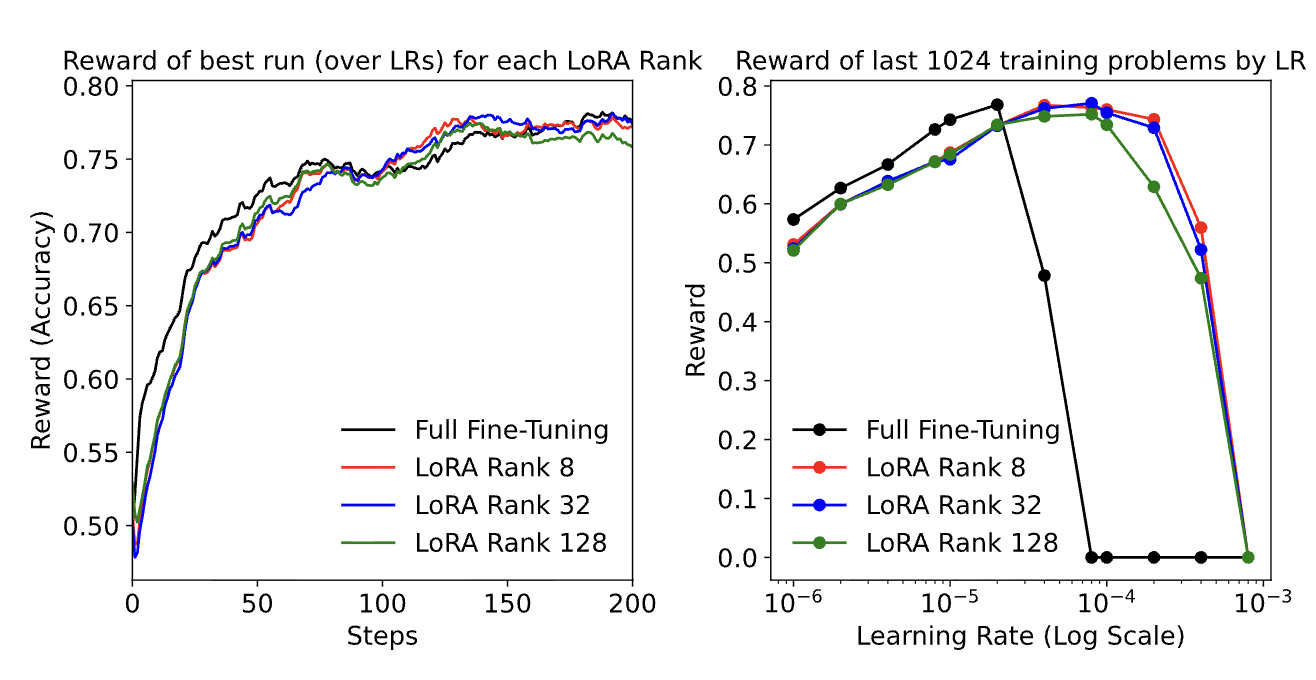
原论文: LoRA 不同 rank vs 全参数微调在 RL 任务上的表现
LoRA (Rank=1) 最终正确率
相对提升 56%, 对比最佳全参数微调基线
Rank-1 LoRA 完全碾压了两种全参数微调配置, 与 Thinking Machines Lab 的发现完全一致。高学习率的全参数微调正确率停滞在 0%。 低学习率的全参数微调在峰值 43.8% 后下降到 33.3%。而 LoRA 在第 50 步就飙升到 56%, 并稳定在 52% 左右。不同的模型和数据集, 同样的结论。
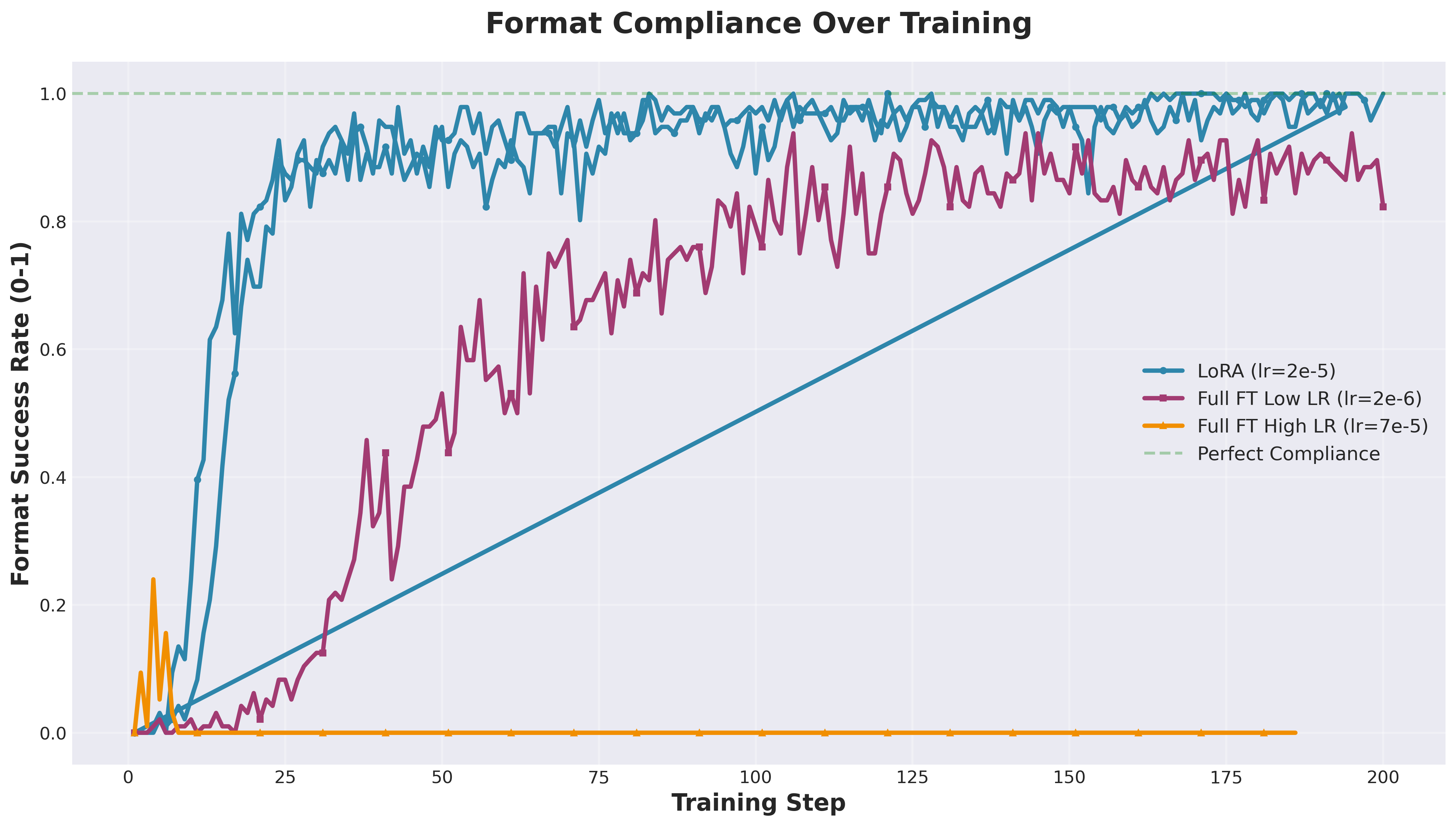
格式合规率: LoRA 在第 100 步达到 100%, 而全参数微调最高仅 82.3%
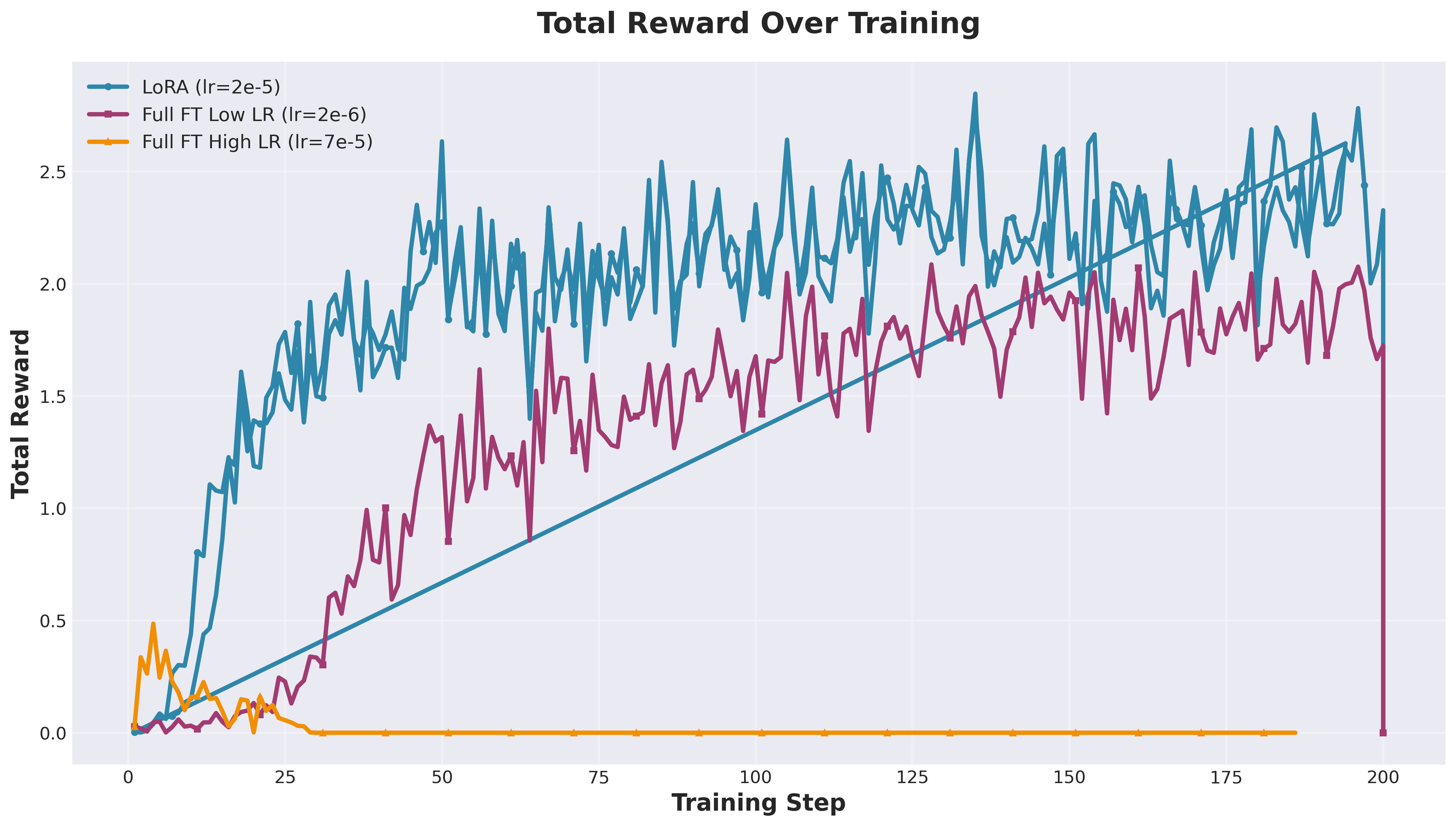
总奖励进展 (正确率 + 格式 + 推理质量)
以下是 RL 微调实验在 Orchestra 中运行的实际演示, 可以看到 Agent 如何搭建环境、配置 GPU 并实时监控训练:
视频: 使用 Orchestra 在 GSM8k 上进行 GRPO 微调, 从搭建到出结果
时间线对比
传统方式
- 第1-3天:租用算力、排队等待集群、配置 GPU 环境
- 第4-7天:编写训练代码、实现 GRPO、调试奖励函数
- 第8-10天:运行实验, 发现配置有误, 重新运行
- 第11-14天:生成图表、撰写分析、制作对比表格
使用 Orchestra
- 傍晚:20 分钟对话, 说明我想测试什么
- 整夜:Agent 编写代码、调试、配置 H100, 并行运行实验
- 早晨:完整结果就绪, 包含图表和分析。发现了 4 个奖励函数问题
- 次日:修复后的实验验证了论文结论, 并附详细分析报告
这是我得到的: 一夜之间完成的生产级实验。代码正常运行, 基础设施正确配置, 指标跟踪准确。唯一的"问题"是我中途改变了奖励权重的想法, 而 Agent 毫无怨言地处理了重新运行。
这省去了数周的工程工作, 这些工作通常会阻碍我探索主要专业领域 之外的方向。我从"想测试这个, 但没有 3 周时间搭建环境"变成了 "让我今天就验证一下", 只用了一个晚上。这就是想法停留在 理论阶段和实际付诸测试之间的区别。
关于 LoRA 的收获
关于研究方式的启示
我们正在重新定义未来的研究方式。
这次经历让一个重要的转变具象化了: 科学的瓶颈正在从"能否运行实验"转向"应该测试什么"。
以前, 很多想法因为执行成本过高而未被验证。一篇论文会激发 对泛化性的好奇, 但验证它需要 2-3 周的基础设施搭建工作, 大多数研究者没有这个时间。
当你能清晰地表述一个研究问题时, 你现在就能得到实证答案。 这使研究者能够追随好奇心, 运行那些原本会被搁置的验证研究, 通过消除不必要的摩擦来加速科学进程, 而不是走捷径。 每个人都可以成为科学家。
参考文献
- LoRA Without Regret — John Schulman 和 Thinking Machines Lab, 2025年9月
- LoRA: Low-Rank Adaptation of Large Language Models — Hu et al., 2021
- Group Relative Policy Optimization — Shao et al., 2024
- GSM8K: Training Verifiers to Solve Math Word Problems — Cobbe et al., 2021
- Tulu 3: Pushing Frontiers in Open Language Model Post-Training — Lambert et al., 2024
实验使用 Orchestra Research 完成, 这是一个 AI 驱动的研究平台, 旨在加速科学发现。 所有代码、配置和实验日志均可用于复现。
引用
如需引用本文, 请使用:
BibTeX
@article{zhang2025lora_reproduction,
title={Reproducing "LoRA Without Regret" with Orchestra},
author={Zhang, Zechen and Liu, Amber},
journal={Orchestra Research Blog},
year={2025},
url={https://www.orchestra-research.com/perspectives/LLM-with-Orchestra}
}致谢
我们感谢 Modal 慷慨提供云计算基础设施支持。他们的平台让按需配置 H100 GPU 变得无缝衔接, 这对于大规模运行监督微调和强化学习实验至关重要。